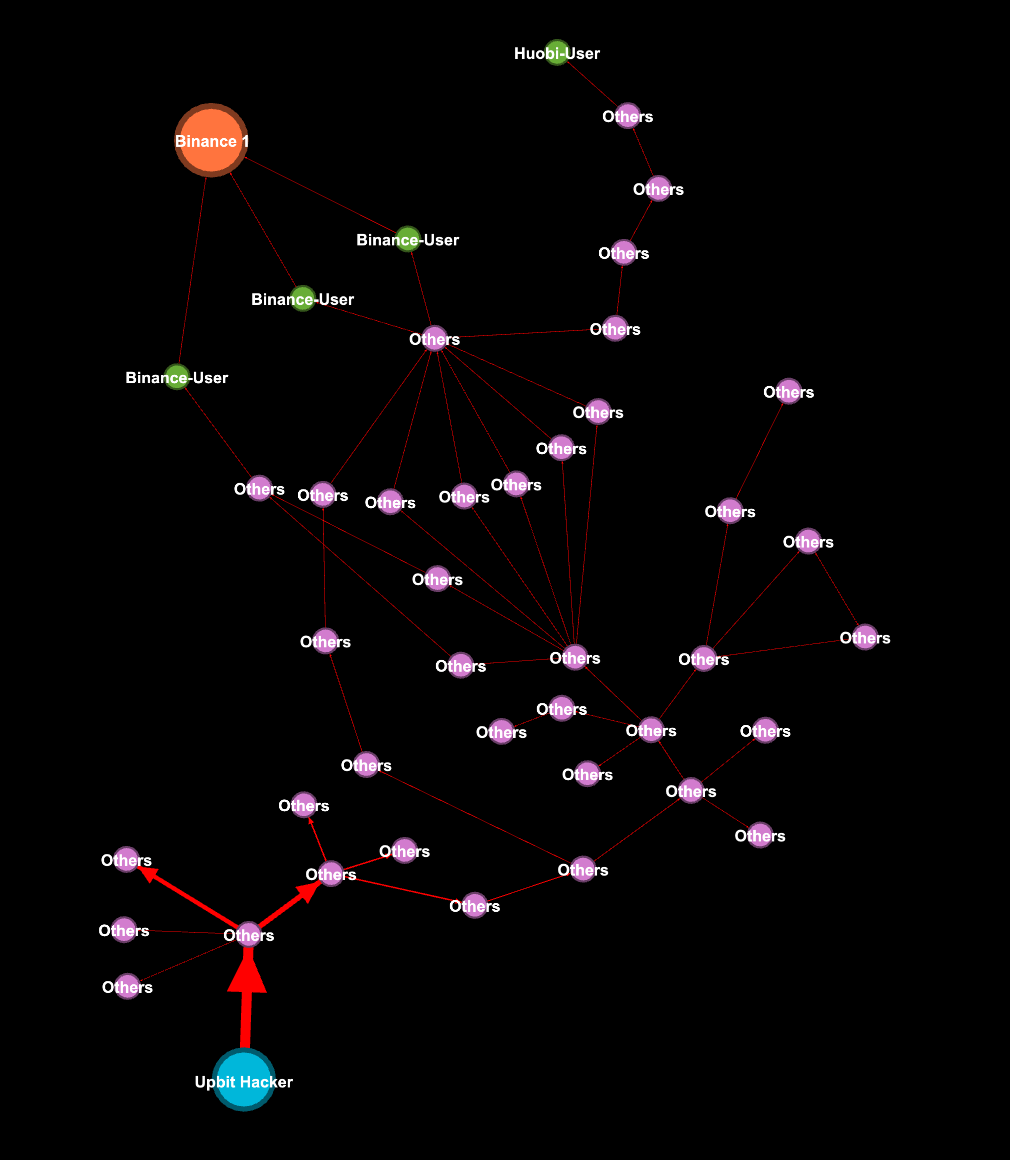
The structure of a blockchain fits very naturally into a graph representation, with addresses being the nodes and transactions being the edges of a graph. By modelling the blockchain as a graph, we can get a comprehensive view of the activities that are on-going and how the different entities are related to each other.
Large scale graph analytics comes with its own set of challenges - we can’t easily sample, generate summary statistics or even visualize it (imagine 1 million points on your screen). In real-world datasets, we are also concerned with other node and edge attributes such as the time of each transaction. How can we solve such large graph problems efficiently and ensure that the solution can be scaled to even larger graphs?
In this blog post, we outline how our engineers tackled one large graph problem - label propagation. Getting this problem right is crucial as it allows Blocklynx, our blockchain graph analytics platform, to discover relationships between millions of blockchain accounts.
By applying our data insights on the blockchain transaction graph and reframing the problem, we were able to achieve an implementation that is least 10x faster and 10x more efficient than most network libraries. Check out the recording of our webinar held last Tuesday or read on to find out how we did it.

What Is Label Propagation?
Wikipedia defines it as a semi-supervised machine learning algorithm that assigns labels to previously unlabeled data points. Check out the illustrated version of the algorithm below. In brief, it takes certain initial attributes and spreads them across the network until convergence.

Label propagation has been used to assign polarity of tweets, detect community structure in networks and extract relationships between entities. For our use case, we were interested in adapting the algorithm to pre-calculate relationships between nodes in the blockchain, so that we can display information between entities on our front-end explorer quickly.
Label Propagation On The Blockchain
Here are some additional technical constraints we faced when applying the algorithm to the blockchain:
- We had to ensure that the propagation follows the time ordering of transaction activities
- The solution should be able to do fast batch computations but also support incremental updates
- We wanted a deterministic solution (different runs with the same parameters should produce the same results)
Most of the academic papers analyzing this problem often focus on a narrow area of the problem without considering other constraints. Hence, we decided to build our own processing pipeline, optimizing various pieces of our technology stack.
Our Solution
Rather than take in information on all addresses and transactions before propagating as most network libraries would do, we modified the algorithm to run within a particular block and timestamp range. This allows us to significantly cut down memory usage and speed up run time as only the necessary data is fed to the machine when needed.
Essentially, we translate the propagation problem to that of a streaming problem where propagation happens in a local block timestamp neighbourhood.
Enjoying the content?
Subscribe to get updates when a new post is published
The problem with the streaming approach is that we still have to look up certain information on the addresses. To reduce the lookup time, we pre-merge the information on the addresses to the edges using Bigquery (Google’s super data crunching analytical database). This allows us to loop through the edges and eliminate the lookup on the address table.
Using Data Insights To Further Optimize The Solution
Can we do even better? Yes, we can - with the additional data insights of our transaction analysis.

Typical of transaction graphs, there are a few actors that tend to be connected to everyone (e.g. the exchanges and the miners in the blockchain network). If we were to scan through the transaction log, we would see the same handful of addresses over and over again while a majority of the addresses would appear in only a handful of transactions.

In addition, if we were to look at the activity of each cohort of addresses, we can see that there is only a small core group of addresses that tends to be active across the months.
We can combine both insights to develop an even smarter and more efficient label propagation algorithm. Our findings suggest that most of the data does not need to be held in memory and inspired us to use a cache to only retain those addresses which are very highly connected, with the rest being stored in disk. This substantially lowered the cost of running the algorithm, without reducing negatively affecting the overall run time.
Summary
Adapting the label propagation algorithm as a streaming problem and applying our data insights on the transaction graph resulted in a 10x speedup and 10x more efficient algorithm.
Over the next month, we are going to increase our coverage of the different entities in the blockchain with our new algorithm. If you have a specific label tracing problem on the Ethereum blockchain, we are here to help - just drop us an email. Also, if you find this problem interesting, we are looking to hire, so do reach out and we can discuss further ways to bring graph analytics to the blockchain.
Enjoying the content?
Subscribe to get updates when a new post is published