What is Machine Learning
“Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” — Nvidia
In short, Machine Learning (ML), a subfield of Artificial Intelligence (AI) is the machine equivalent of learning from one’s mistakes. Just as past experiences inform our decisions in the present, data is the key to modelling and predicting real-world outcomes. This data-driven approach to ML that is familiar to us today was only able to emerge from the exponential growth of data and storage capacity in the 1990s.
The promises of ML have resulted in rapid adoption by businesses across industries. Use cases include forecasting of sales, autonomous vehicles, fraud detection and even more recently, the testing effectiveness of Covid-19 vaccine.

In this article, we do a deep dive on how ML is used for fraud detection especially within the finance industry and explore key questions which businesses have to consider when adopting such technologies.
Advantage of ML Methods vs Rule-based Methods (why ML?)
Traditionally, the finance industry has relied on rule-based methods to screen for financial fraud. A rule-based system is logical & intuitive; you hardcode the rules, typically relying on a domain expert’s opinions, to produce pre-defined outcomes. ML, on the other hand, does not produce any explicit rules. Outcomes and rules vary on data that is fed into the ML model. To elaborate, we will look into the chart, which shows the differences of the 2 methods in catching fraudulent individuals.
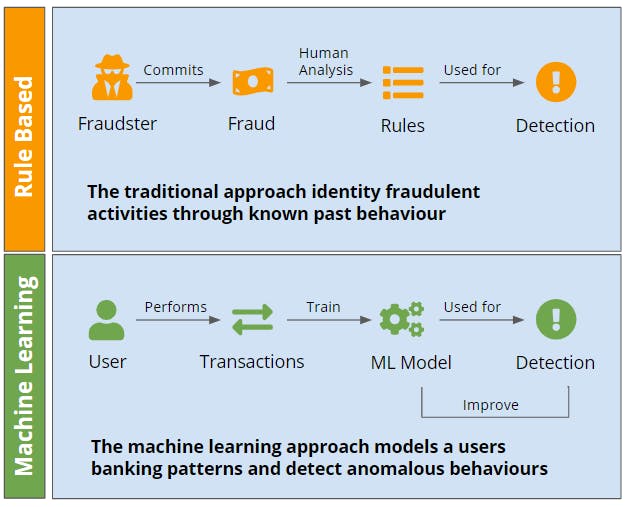
The rule-based approach involves a team of experts identifying stereotypically fraudulent behaviour before converting them to rules which are used for transaction screening. This could range from flagging transactions coming from certain countries of origin or a fixed value threshold.
There are two main problems with such an approach - effectiveness and efficiency. Effectiveness - bad actors are constantly devising new ways to circumvent existing rules and many will be able to bypass a fixed set of criteria. To flag up a greater number of these suspicious activities, rules need to be set at a relatively low threshold. This means lots of manpower needs to be relied upon to screen through the flagged cases manually, a thoroughly inefficient process. For example, a McKinsey study reported that personnel cost accounted for more than 75% of compliance cost, with many increasing headcount to better comply with more stringent regulations in the space.

Rather than modeling fraudulent activity, we can model typical users’ behaviour data which financial institutions have abundant data on. This allows us to identify abnormal or suspicious activities which might not have been captured by the rule-based system. Another advantage of such an approach is that the model building and scoring process can be updated much more frequently and regularly than rules.
In the regulatory compliance landscape, we commonly see companies adopting both approaches - rule-based to cater to existing regulatory needs and AI-based for case prioritization and efficiency. The ML pipeline can be used to prioritise cases, freeing up tremendous time from dealing with low-risk cases and allowing a compliance team to focus on the higher-risk ones. The model scores and output can also be used as a decision support system to inform the analyst of the probable cause of suspicious activity, improving case efficiency.
Enjoying the content?
Subscribe to get updates when a new post is published
Applications of ML for Fraud Detection
Let’s take a look at 2 interesting real-world applications, where ML is used to help businesses through fraud detection. In 2016, Mastercard employed ML and AI technologies to combat significant losses resulting from risk assessments using predefined rules. The study shows that merchants lose approximately $118 billion per year due to false declines (false negatives) arising from suspected fraud. This had a heavy impact on both the retailers and banks as customers either stopped shopping or switched their bank after their payments were falsely declined. By implementing an AI-based detection framework to identify abnormal spending patterns based on merchant location, device data and purchase information, the project went on to cut the losses by around 50%.

The second example focuses on detecting forged signatures. Every year, banks lose more than $600 million due to check fraud, a third of it due to forged signatures. Besides the regular checks, most banks are now deploying state-of-the-art deep learning methods (a type of ML technique often associated with image detection or natural language processing) to catch the impostors. Checks range from analysing the position and amount of curvature of a signature to even using motion sensors to track the person's angle and movement of the hand.
Considerations when applying ML for fraud detection
In the process of ML model development, two dilemmas will require businesses to carefully evaluate their business goals and pick sides. The first of these is choosing the model’s sensitivity, more technically known as the precision/recall trade-off of ML models. Precision is simply the proportion of true fraudulent cases out of all the cases that are flagged by the model, while recall captures the proportion of fraud cases flagged out of all the known fraud cases. By making the model more sensitive in flagging out cases, it will most often result in more false positives, or poorer model precision. Establishing an appropriate threshold is an important business question that hinges upon how costly a false positive or false negative case is.
The second dilemma concerns batch vs real-time data processing. In instances where businesses rely on data that is transient, has relevance that fades quickly, or is of such a large volume that it cannot be stored, then real-time processing might be an appropriate methodology. However, it also poses a slew of considerable challenges for businesses, from expensive data infrastructure development, to requiring atypical ML expertise to cope with the data storage limitations of online systems.
In addition to these technical dilemmas, the social dilemma of increasing ML adoption has also been widely reported on in recent years. Perhaps most infamously, the tendency of ML algorithms to internalise racial and gender prejudices. Increasingly, regulators are putting pressure on financial institutions to ensure the fairness of their AI systems. In November 2019, the Monetary Authority of Singapore (MAS) announced that it would be partnering with the financial sector to develop a framework for responsible AI and ML-powered data analytics. For businesses, we believe that transparent and explainable AI methods must be part of the way forward.
Conclusion
Financial institutions are rapidly adopting such technologies to improve cost efficiency and screening effectiveness. We hope this article gives you a good sense of how automated fraud detection techniques could be a good fit for your business as well as some key considerations to keep in mind. At Cylynx, we help companies build and deploy machine learning models for fraud detection. If you are considering an AI-driven approach to compliance and risk screening, contact us for a free consultation to explore how your internal data can be used to augment fraud detection capabilities.
Enjoying the content?
Subscribe to get updates when a new post is published




